LLM (Large Language Model)이란?
LLM (Large Language Model)은 인공지능(AI) 분야에서 사용되는 대규모 언어 모델로, 방대한 양의 텍스트 데이터를 학습하여 언어를 이해하고 생성하는 데 특화된 모델이다. LLM은 자연어 처리(NLP) 기술의 중심에 있으며, 인간의 언어를 기반으로 여러 작업을 수행한다.

LLM의 주요 특징
1. 대규모 데이터 학습
- 인터넷, 책, 논문 등 다양한 출처에서 수집된 수십억~수조 개의 단어 데이터를 학습함.
- 학습 데이터가 많을수록 모델이 더 다양한 언어 패턴과 컨텍스트를 이해할 수 있음.
2. 트랜스포머(Transformer) 구조
- LLM은 주로 트랜스포머 기반 아키텍처(GPT, BERT 등)를 사용함.
- 트랜스포머는 문맥을 이해하는 데 뛰어난 성능을 제공하며, 병렬 처리가 가능해 학습 속도도 빠름.
3. 다양한 언어 처리
- 텍스트 생성, 번역, 요약, 질의응답, 문법 교정 등 다양한 작업을 수행가능.
- 예: GPT 계열 모델 → 텍스트 생성
BERT 계열 모델 → 텍스트 이해
- 예: GPT 계열 모델 → 텍스트 생성
4. 파라미터 수
- LLM은 수백억~수조 개의 파라미터를 가지며, 이는 모델이 얼마나 복잡한 관계를 학습할 수 있는지 나타냄.
- 예: GPT-3는 약 1750억 개의 파라미터를 가지고 있음.
LLM의 주요 용도
- 자연어 생성:
- 블로그 글쓰기, 소설 작성, 기술 문서 작성 등 자연스럽고 유창한 텍스트 생성.
- 자동 번역:
- 여러 언어 간의 고품질 번역 제공.
- 질의응답(Q&A):
- 사용자의 질문에 대해 맥락에 맞는 답변 생성.
- 대화형 AI:
- 챗봇이나 가상 비서를 구현하는 데 활용 (예: ChatGPT, Alexa).
- 텍스트 분석:
- 감정 분석, 문장 요약, 주제 분류 등.
LLM의 한계
- 학습 데이터에 의존:
- 학습 데이터에 없는 지식이나 정보는 생성할 수 없으며, 종종 부정확한 답변을 생성 가능.
- 비용 문제:
- 모델을 학습시키는 데 많은 시간, 데이터, 컴퓨팅 자원이 필요함.
- 편향(Bias):
- 학습 데이터의 편향성이 모델의 결과에도 반영됨.
- 추론 능력 한계:
- 창의적이거나 복잡한 논리적 추론에서 한계를 보일 수 있음.
RNN (Recurrent Neural Network)
1. RNN의 개념
- RNN은 Recurrent Neural Network의 약자로, 시퀀스 데이터(시간 또는 순서 의존성이 있는 데이터)를 처리하기 위해 설계된 신경망임.
- 주요 특징은 순환 구조를 가지고 있어 이전 시간 단계의 정보를 저장하고, 이를 현재 단계의 입력으로 사용함.
- 텍스트, 음성, 시계열 데이터 같은 순차 데이터에서 매우 유용함.
2. RNN의 구조
입력 xt와 이전 단계의 은닉 상태 ht-1가 결합하여 현재 은닉 상태 ht를 계산.
공식:ht = Activation(Wxxt + Whht-1 + b)
Wx:입력에 대한 가중치.Wh:은닉 상태에 대한 가중치.b:편향.
3. RNN의 한계
- Vanishing Gradient Problem: 시퀀스가 길어질수록 초기 정보가 사라져 모델이 학습하기 어려움.
- Long-Term Dependency 처리의 어려움: 장기적인 문맥 정보를 기억하는 데 한계가 있음.
MLP (Multi-Layer Perceptron)
1. MLP의 개념
- MLP는 다층 퍼셉트론의 약자로, 기본적인 Feedforward Neural Network.
- 비시퀀스 데이터에서 널리 사용되며, 입력 데이터와 출력 데이터 간의 고차원 비선형 관계를 학습할 수 있음.
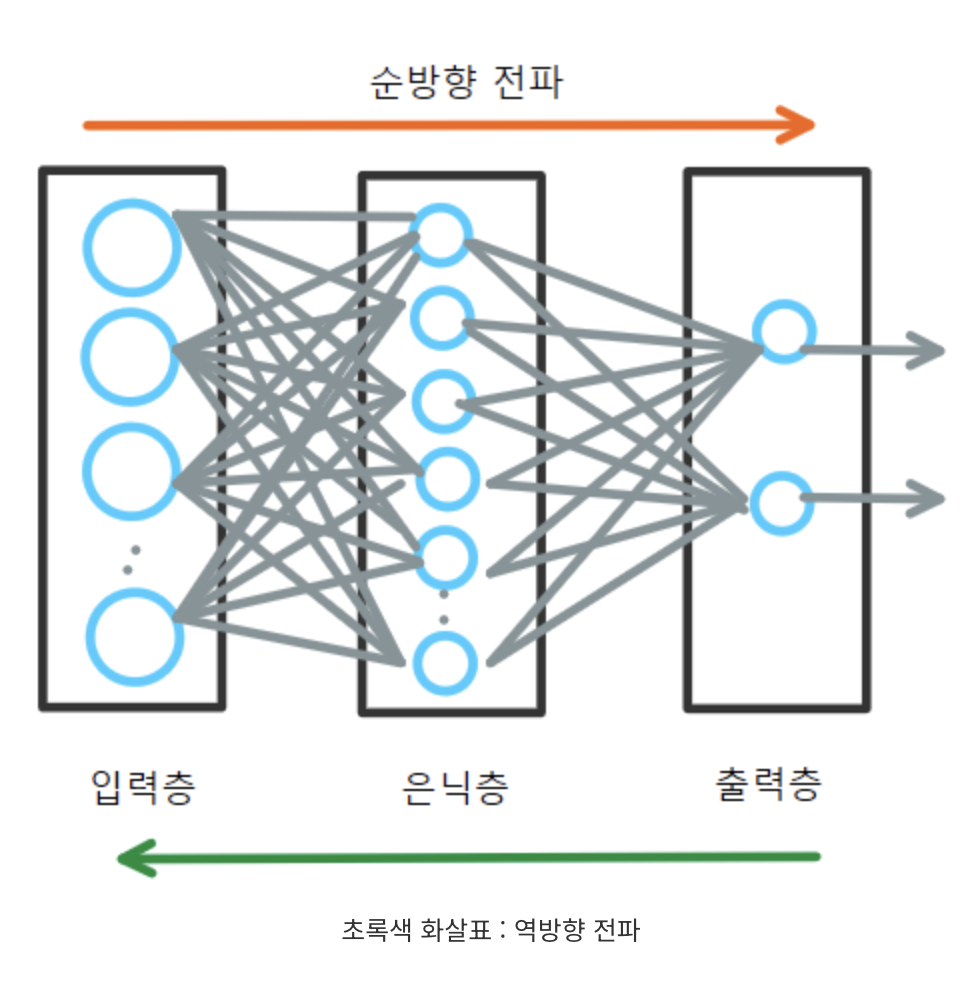
2. MLP의 구조
기본적으로 Fully Connected Layer와 Activation Function으로 구성됩니다. 입력층 → 은닉층(들) → 출력층 구조로 되어 있으며, 각 노드는 이전 층의 모든 노드와 연결되는 형태.
공식:h = σ(Wx + b)
W:가중치 행렬.b:편향.σ:비선형 활성화 함수(e.g., ReLU, Sigmoid).
3. MLP의 한계
- 시퀀스 데이터 처리 불가: 순서나 시간 의존성을 반영하지 못함.
- 고정된 입력 크기: 유연한 입력 길이를 다룰 수 없음.
그럼 여기서 기존의 LLM은 RNN 을 왜 사용하고 Transformer로 교체한 이유를 정리해보자.
LLM에서 RNN을 사용하는 이유
1. LLM과 시퀀스 데이터
- LLM(Large Language Model)은 텍스트와 같은 순차적 데이터를 처리합니다. 이는 단어의 순서, 문맥, 의미 등이 중요하기 때문에, 시퀀스 의존성을 학습하는 것이 필수적입니다.
- RNN은 텍스트 데이터의 순차성과 문맥을 학습하는 데 특화된 구조.
2. RNN의 역할
- RNN은 단어 간의 관계와 문맥적 의미를 이해하기 위해 LLM의 초기 설계에 자주 사용되었습니다.
- 예: 한 문장에서 각 단어의 순서에 따른 의미를 학습하거나, 문장의 다음 단어를 예측.
- 단, RNN만으로는 한계가 있었습니다. 장기 의존성을 처리하지 못하고, 학습 속도가 느렸으며, 병렬 처리가 어렵다는 문제가 있음.
RNN의 한계를 해결하기 위한 대안: Transformer
최근의 LLM(GPT, BERT 등)은 Transformer 구조를 사용하며, RNN을 대체함. Transformer는 다음과 같은 이유로 RNN보다 효율적:
- 병렬 처리 가능:
- RNN은 순차적으로 학습해야 하지만, Transformer는 모든 입력을 병렬로 처리할 수 있음.
- Long-Term Dependency 처리:
- Self-Attention 메커니즘을 통해 긴 문맥도 쉽게 학습 가능.
- Vanishing Gradient 문제 없음:
- Transformer는 깊은 네트워크에서 더 안정적으로 학습.
결론: 왜 LLM에서 RNN을 대체했는가?
RNN은 순차적 데이터를 처리하는 데 강점이 있지만, LLM에서 요구하는 대규모 데이터 학습과 긴 문맥 이해에는 적합하지 않기에, Transformer 기반 모델(예: GPT, BERT)의 기반으로 대체가 되었다고 한다.
Reference:
리디렉션 알림
www.google.com
https://jitolit.tistory.com/107
MLP 신경망 (Multi-Layer Perceptron)
MLP 란 여러 개의 퍼셉트론 뉴런을 여러 층으로 쌓은 다층신경망 구조입력층과 출력층 사이에 하나 이상의 은닉층을 가지고 있는 신경망이다.인접한 두 층의 뉴런간에는 완전 연결 => fully connected
jitolit.tistory.com
'[Personal studies]' 카테고리의 다른 글
| [Personal studies] ECG(EKG), EEG 간단정리 (1) | 2025.03.05 |
|---|---|
| [Personal Studies] HTTP && TCP && IP (0) | 2025.03.03 |
| [Personal Studies] Monolithic && Microservice 정리 (0) | 2025.03.03 |
| [Personal studies] RESTful API Note (0) | 2025.03.03 |
| [Personal studies] Agentic AI란? (3) | 2025.01.15 |